Es ist eigentlich ein alter Hut, aber regelmäßig stolpere ich über Fälle, wo Webmaster oder SEOs Probleme mit dem korrekten Einsatz von robots.txt und dem noindex-Metatag haben. Das größte Problem dabei ist der Glaube, dass eine in der robots.txt ausgesperrte URL nicht indexiert werden könne. Das ist falsch! Die robots.txt ermöglicht lediglich eine Steuerung des Crawlers; der historische Zweck der robots.txt war, den Crawler von den Bereichen der Website fern zu halten, die eine besonders hohe Serverlast erzeugten. Der Nebeneffekt dabei: die per robots.txt „geschützten“ URLs konnten nicht in den Index gelangen.
Das aber gilt schon lange nicht mehr. Denn Google misst Links eine so hohe Bedeutung zu, dass bereits ein Link auf eine URL reichen kann, diese URL aufzunehmen. Dazu muss Google die verlinkte URL noch nicht einmal besucht haben. Auf diesem Weg also können URLs im Index landen, die in der robots.txt auf „Disallow“ gesetzt sind.
Dass dies nicht nur bloße Theorie ist, lässt sich schnell überprüfen. Schauen wir uns mal die robots.txt von idealo.de an:

zum Vergrößern anklicken
Dort ist die Zeile Disallow: /preisvergleich/MainSearchProductCategory/enthalten. Nach klassischer Vorstellung sollte also keine URL von idealo.de, die mit /preisvergleich/MainSearchProductCategory/ beginnt, im Google-Index enthalten sein.
Allerdings belehrt uns eine entsprechende site:-Suche schnell eines besseren:
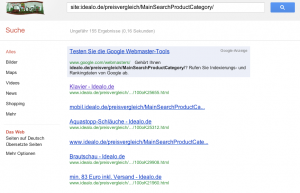
Offenbar folgte Google Links auf diese URLs und fand die Links so überzeugend, dass die verlinkten URLs im Index gelandet sind. Doch woher kommen die Titel wie „Klavier“ oder „Brautschau“, wenn doch die URLs nicht gecrawlt werden dürfen? Das sind keine Informationen aus dem Title-Tag der jeweiligen Seite, sondern das ist lediglich der Linktext, den Google hier heranzieht, um eine schönere Ergebnisdarstellung zu erreichen. (Das macht Google inzwischen manchmal sogar bei crawlbaren Seiten, wenn die Suchmaschine der Ansicht ist, dass der vorhandene Title-Tag zu nichtssagend ist. Sozusagen SEO-on-the-fly by Google himself …)
Wir haben bisher also gelernt, dass ein robots.txt-Disallow-Eintrag nicht vor einer Indexierung schützt. Nun, dann nutzen wir doch einfach den Noindex-Metatag. Wir setzen also eine solche Zeile in den HTML-Code unserer Seite:
<meta name="robots" content="noindex">
Doch was passiert nun? Gar nichts! Denn dank der Disallow-Anweisung in der robots.txt-Datei wird Google nie von der Existenz dieser Anweisung erfahren. Schließlich verbieten wir Google ja, diese URL zu crawlen und den Inhalt zu untersuchen. Der Einsatz von robots.txt und des Noindex-Metatags widerspricht sich also häufig.
Wie aber setzen wir diese beiden Werkzeuge richtig ein?
Die robots.txt ist überall dort sinnvoll, wo wir verhindern wollen, dass ein Crawler auf die geschützten URLs zugreift. Dies kann sein, um Bilder von der Aufnahme in Suchmaschinen auszuschließen oder um einen besonders ressourcenintensiven Teil der Webanwendung vor Überlastung zu schützen. Auch wenn wir eine große Anzahl an für Suchmaschinen vollkommen belanglosen URLs (Stichwort: Duplicate Content) haben, kann uns die robots.txt nützen. Denn damit verhindern wir, dass der Crawler sich mit diesen URLs verlustiert und anschließend keine Ressourcen mehr für die wichtigen Seiten übrig hat. Wir müssen aber damit leben, manche URLs trotzdem im Google-Index zu sehen.
Möchten wir aber sicherstellen, dass bestimmte URLs nicht im Index auftauchen, müssen wir den noindex-Metatag einsetzen, den Suchmaschinen aber den Zugriff auf diese URLs erlauben. So kann Google die Noindex-Anweisung erkennen und beachten.
In beiden Fällen könnten wir noch theoretisch mit Nofollow-Links dafür sorgen, dass Google sich mit diesen URLs möglichst erst gar nicht beschäftigt. Da das Nofollow-Attribut aber nur eine Empfehlung ist, an die sich Google häufig nicht hält, können wir uns das auch sparen. Zumal eine Website, die mit Nofollows übersät ist, auf Google auch nicht besonders überzeugend wirken dürfte.